Look at Central Limit Theorem
When collecting data, the data would inevitably be affected by noise. Looking deeper, noise is made up by the summation of random and independent processes (eg. thermal process, electro-magnetic interferences etc). Thus based on the Central Limit theorem, Noise should follow a Normal distribution.
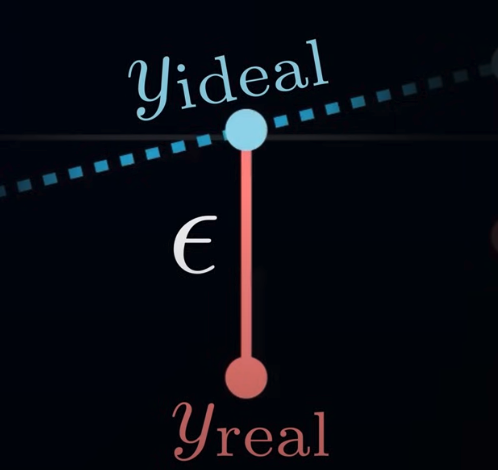
Typically, the mean () of noise is assumed to be 0. Since each individual processes are random in nature, they have an equal likelihood of having a positive and negative magnitude. Thus, the noise should have no biases in the positive or negative direction.
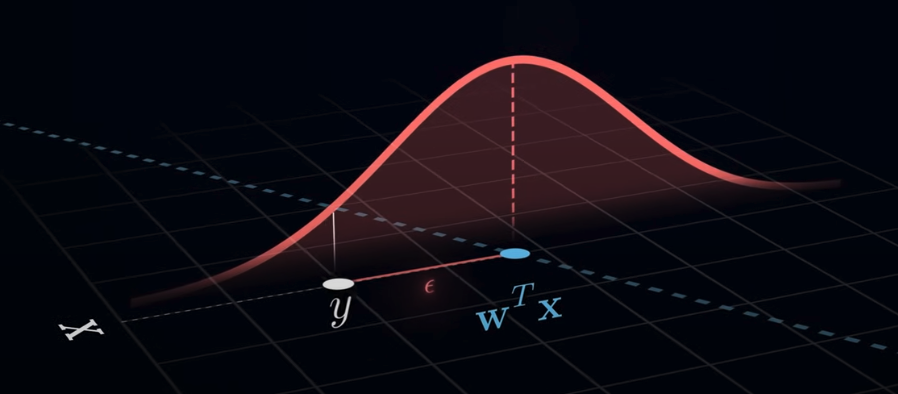
The probability of observing an error of value is given as
The above shows the normal distribution denoted in red , where is . It basically states the greater the , the lower the probability of its occurrence and vice versa.
Suppose is a linear equation
Optimising the weights
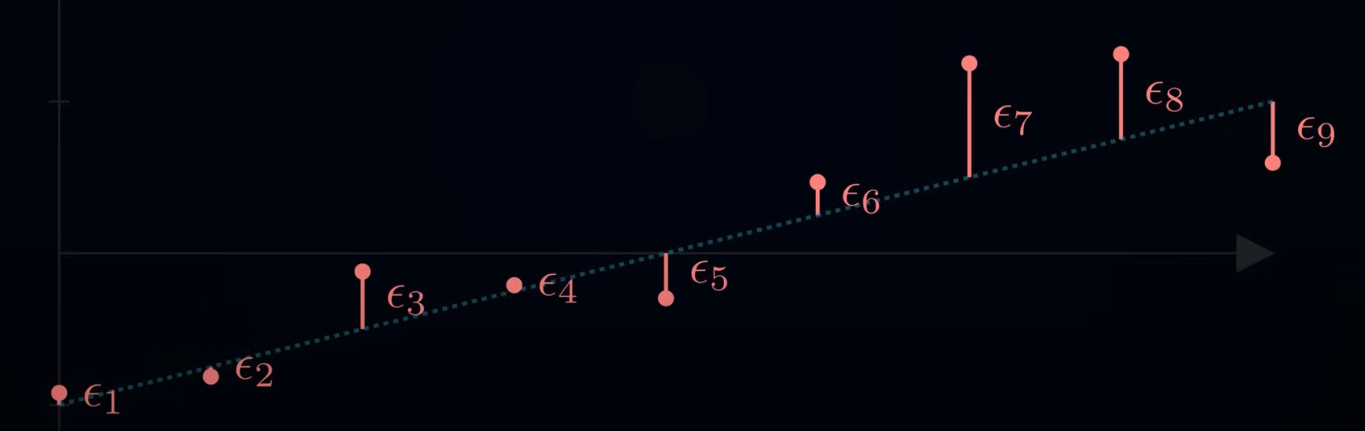
For independent events, the probability of multiple events occurring is just the product of all its probabilities.
Thus the probability that we observe the following data above is
We can rewrite it as
Since the smaller the , the higher the probability of its occurrence . If we maximise , that would minimise .
Thus can be achieved when we maximise .
is an operation that finds the argument (or input) that yields the maximum value of a function. Thus we aim to find the input weights () or coefficients of that maximises .
The argument that maximises is the same as the argument that maximises of as, if then .
Hopefully you understand that taking out the constants and will still provide an argument that maximises .
Thus
This is the exactly the Mean squared error formula used in textbooks. And we have proved that finding the argument , that minimises is the best at minimising error .